Protocol-andia: Welcome to the Networking Neighborhood
A whimsical introduction to how computers talk to each other, and what exactly your requests are up to.
February 19, 2019 • 4434 words • 16 minute read • Read on Medium
In the wide, wild world of the web, there’s a lot of devices that want to talk to each other.
This blog post lives on some computer somewhere in the world, and you’re reading it on your own device in your own corner of the planet. So how did the words and pictures get from there to here?
🤝 Protocols for fun and profit

Gif of Lindsay Lohan and Simon Kunz in The Parent Trap movie doing a complicated multi-step handshake with some dance moves involved. (source)
{kind=link}
Protocols are contracts for communication, a series of steps and actions that define a process of sending or receiving information.
Protocols are a bit like secret handshakes. You have to know your part in order for the whole thing to work. Some protocols are more complex than others, and each one has a different purpose — you might even need to use multiple protocols, one built on top of another, to accomplish your goal!
If you’re writing web applications, you typically don’t need to worry about the exact details— most of the time, you’re going to use libraries and tools that handle the specifics. It’s valuable to have some familiarity with the common protocols, and a general idea of what they do and when you use them!
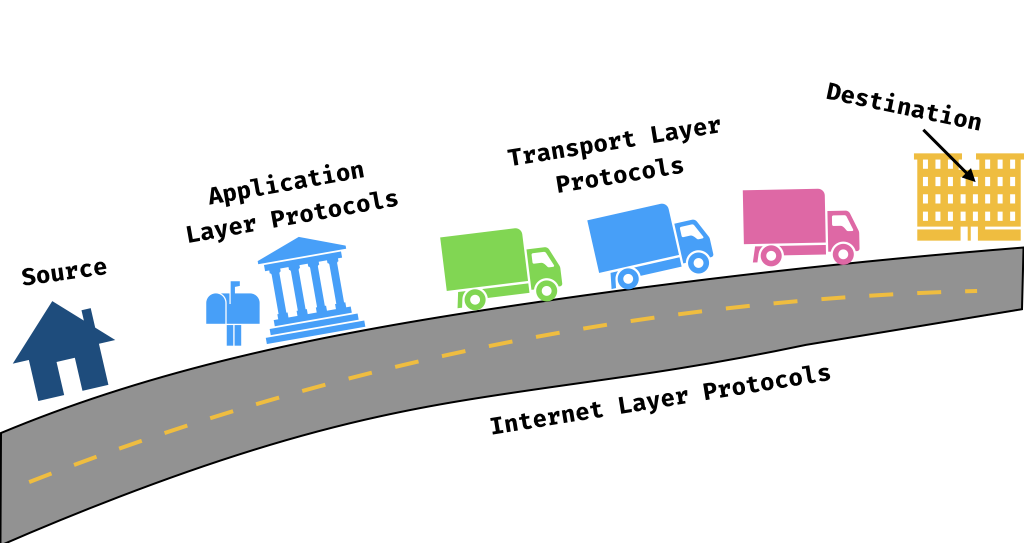
Internet Protocol (IP)
The Internet Protocol is the underlying foundation of how devices are connected and can communicate to each other across networks. It’s just one of many protocols at the Internet layer of networking.
One of its primary responsibilities is routing, or passing data from a source to a recipient across the network. To this end, the Internet Protocol defines IP addresses — unique series of numbers that address a specific physical machine in the network.
For example, 127.0.0.1 is a special IP address that means “this computer,” commonly referred to as localhost. Most other IP addresses refer to a specific machine, and can be used to uniquely identify or fingerprint a device that is accessing the internet. You can find your device’s IP address using a tool like WhatIsMyIP.com.
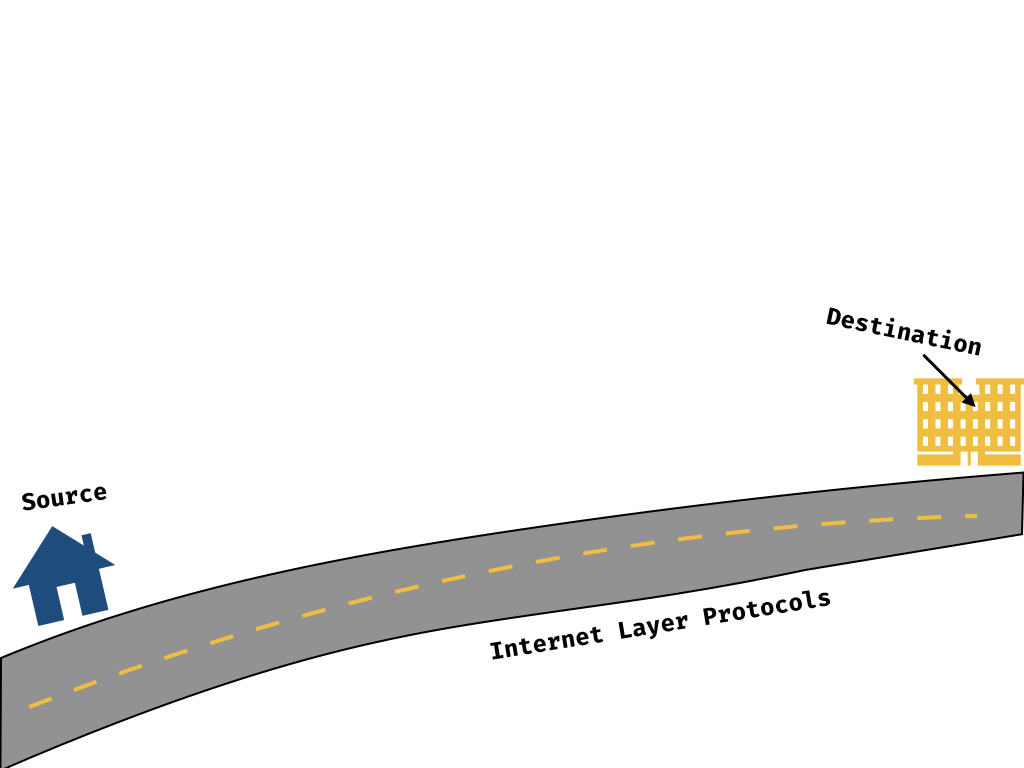
The Internet Protocol is a bit like a network of highways and streets, complete with street signs. We can think of IP addresses as street addresses — unique ways of identifying each building and destination we can interact with.
It’s worth noting that IP addresses can change! Just like street addresses aren’t geographical coordinates, IP addresses are an abstraction that helps route to a specific device.
Side note: you don’t have to know IP addresses in order to visit websites thanks to the magic of the Domain Name System (DNS), a protocol that maps human-readable domains like
www.mariechatfield.comto the IP addresses where those sites can be accessed!
While the Internet Protocol is powerful and provides a great infrastructure, it doesn’t have a lot of guarantees. Roads can change, or be under construction, or shut down entirely. You can send packets (tiny chunks of data that are small enough to transmit) wherever you want, but you might not ever know whether they arrived or if they got lost in transit.
So the Internet Protocol defines a network of streets and addresses that lets you route between them, but it’s up to you to navigate. What then are the cars driving on those roads?
Transmission Control Protocol (TCP)
The Transmission Control Protocol is built on top of the Internet Protocol, and is part of the Transport layer of networking. It handles breaking larger messages into packets that can be sent across the internet, and providing some stronger guarantees about their delivery.
Have you ever seen a wind turbine in transit? A turbine is a massive structure, far too large to ship fully assembled. Each individual blade is driven on a single 18-wheeler truck to its destination, where it can be assembled and put back together.

Timelapse gif of a wind turbine being assembled by a crane in a field. (source)
If the Internet Protocol is our highway system, the Transmission Control Protocol is the shipping logistics company that breaks down your messages into pieces that fit on its trucks, drives them to your destination, and then reassembles the whole thing for you once it arrives.
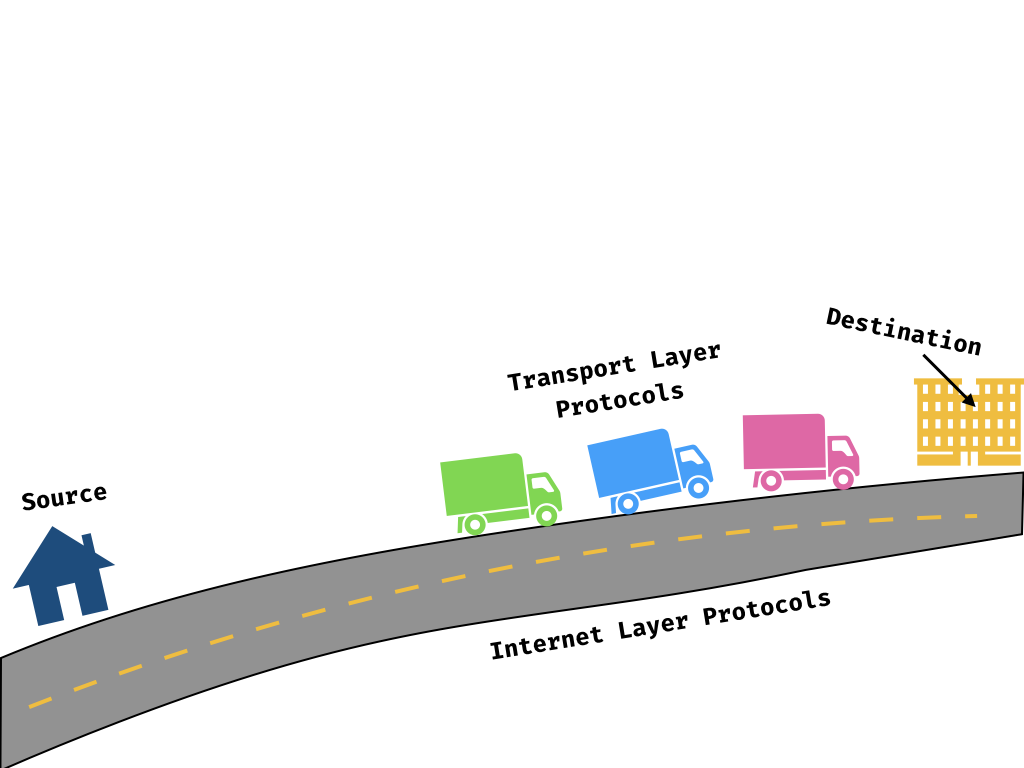
Just like trucks carrying wind turbine pieces, data packets might arrive out of order — or some of them could get totally lost in transit. The Transmission Control Protocol has processes to handle all of these edge cases, so all you have to worry about is saying “send this message to this place, and let me know if it arrived in one piece or not.”
The Transmission Control Protocol defines ports as a way to identify the exact location within a physical machine where you’re sending messages. Think of an apartment building: hundreds of people share the same street address, but you want to send a package to just one of those units.
For example, you might have three servers running on your local machine — one on port 4000, one on port 4001, and another on port 3200. To send a message to the server listening to port 4000, you would address 127.0.0.1:4000.
In our metaphor world, the Internet Protocol is the highway system, and the Transmission Control Protocol is the shipping logistics company. However, most of us aren’t calling up the shipping logistics company directly— we go to the post office instead. Who’s the post office in this world?
Application Layer Protocols
While the Internet and Transport layer protocols provide valuable infrastructure, a lot of the really fun stuff for application developers happens at the Application layer of networking!
Most of these application layer protocols are implemented on top of the combination of the Transmission Control Protocol and the Internet Protocol (referred to as TCP/IP), but they can use any combination of protocols that provide the basics of sending messages across the internet.
For example, Transport Layer Security (TLS) is a protocol that encrypts data while in transit. Many application layer protocols offer a secure version that uses TLS in conjunction with TCP/IP to protect user data.
Side note: if you’re building any kind of application that stores or sends user data, you should absolutely without question use TLS and other encryption protocols to protect the people who interact with your site!
Encryption takes only a little bit more effort to set up and has immense gains for security. Let’s Encrypt even offers free certificates to help you get started.
And of course, never ever provide your own sensitive data to a site without encryption. Many modern browsers even show a helpful little lock at the top of a site to let you know if it’s safe to use or not!
We can think of application layer protocols as our friendly local post offices, which offer a wide variety of services and features to meet our needs. They provide a nice abstraction around the precise details of how our mail travels. We just know that we have a post office box that gets packages, and an easy way to post our own wind turbines and manuscripts and cat photos and travel postcards.
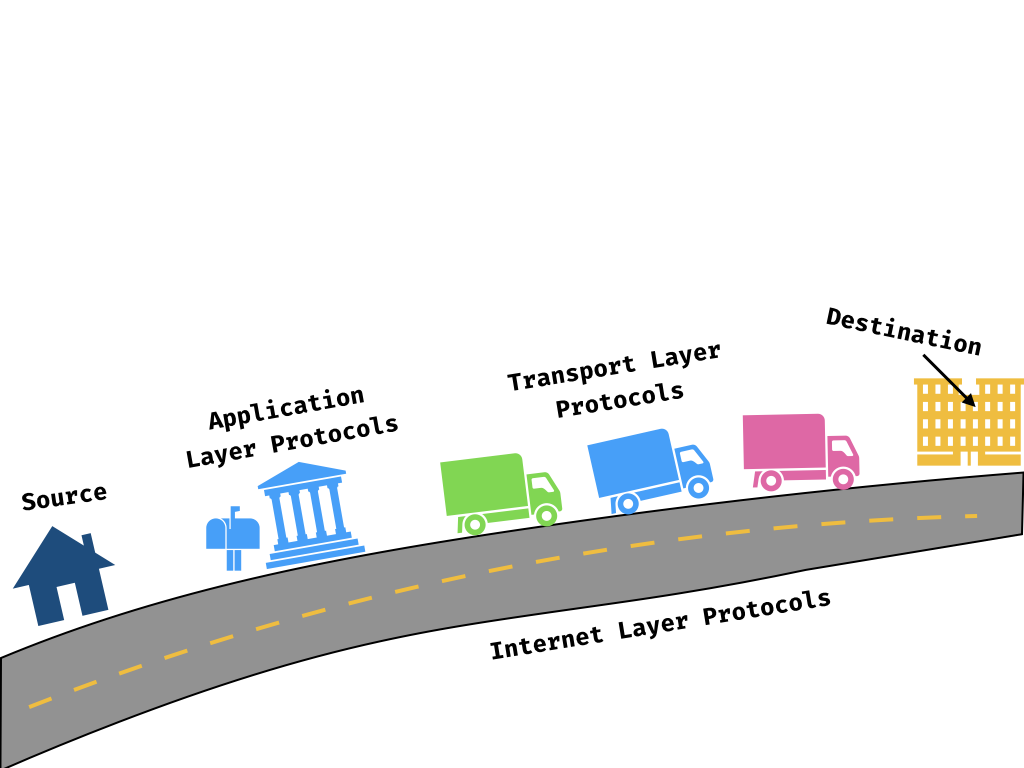
Some common protocols:
- HyperText Transfer Protocol (HTTP) defines requests and responses used to send content for websites (this is our fave protocol as web developers 💛). The encrypted version, HyperText Transfer Protocol Secure (HTTPS), uses the same request/response structure but is built on top of the TLS protocol to protect user data in transit.
- Post Office Protocol version 3 (POP3) and Internet Message Access Protocol (IMAP) allow you to retrieve emails from your email provider so you can read them locally.
- Simple Mail Transfer Protocol (SMTP) allows you to send new emails via your email provider.
- All three of these email protocols offer secure versions built on top of TLS to protect email content while sending messages!
- Secure Shell (SSH) allows you to log onto other machines remotely and securely run commands. It’s not built on top of TLS, but uses its own encryption protocols.
- File Transfer Protocol (FTP) is a method to share and transfer files, like a remote file directory. The encrypted version, Secure File Transfer Protocol (SFTP), uses the SSH protocol under the hood.
All of these protocols are useful, and using any of them depends on having a server that implements the protocol in question!
🤔 When you say server… what do you mean?
A server is just a process that continually runs on some machine somewhere in the world, listening to messages addressed to a specific TCP port, and responding in a (hopefully) expected way.

Gif of Alana “Honey Boo Boo” Thompson on the TV show “Here Comes Honey Boo Boo” answering the phone with caption “How may I help you?” (source)
Most protocols specify which port they expect an implementing server to listen to— for example, HTTP servers are usually on port 80 and SSH servers are on port 22.
You can have multiple servers running on the same physical machine! For example, you might have an HTTP server running your main web application, an FTP server to host large files, and IMAP and SMTP servers running your own private email system.
Most of the time in the web development world, we use server as a shorthand for “HTTP server”, but it’s helpful to remember that’s not the only kind of server or protocol out there. But since HTTP is our bread and butter as web developers, let’s dive a bit deeper into the details!
✨ HTTP-topia is a magical place ✨
HTTP is the primary application layer protocol we use as web developers to retrieve resources to render websites. Everything (and I do mean everything) in a website is delivered via HTTP to the browser, from HTML and images to JavaScript files and data.
HTTP defines two message types: requests and responses. A client makes a request to a server, and the server sends back a response.
A client is anything that makes a request — usually a browser, but servers can also make HTTP requests to other servers! A client can also be something like a web crawler bot or a command-line tool like cURL.
If HTTP is our local post office, requests and responses are the postcards!


A sample HTTP GET request and response pair, presented as illustrations of postcards sent between the client and the server. The client requests path emojis?type=food and the server responds with a 200 status code and a JSON string with emoji names and icons for taco, sushi, and mango.
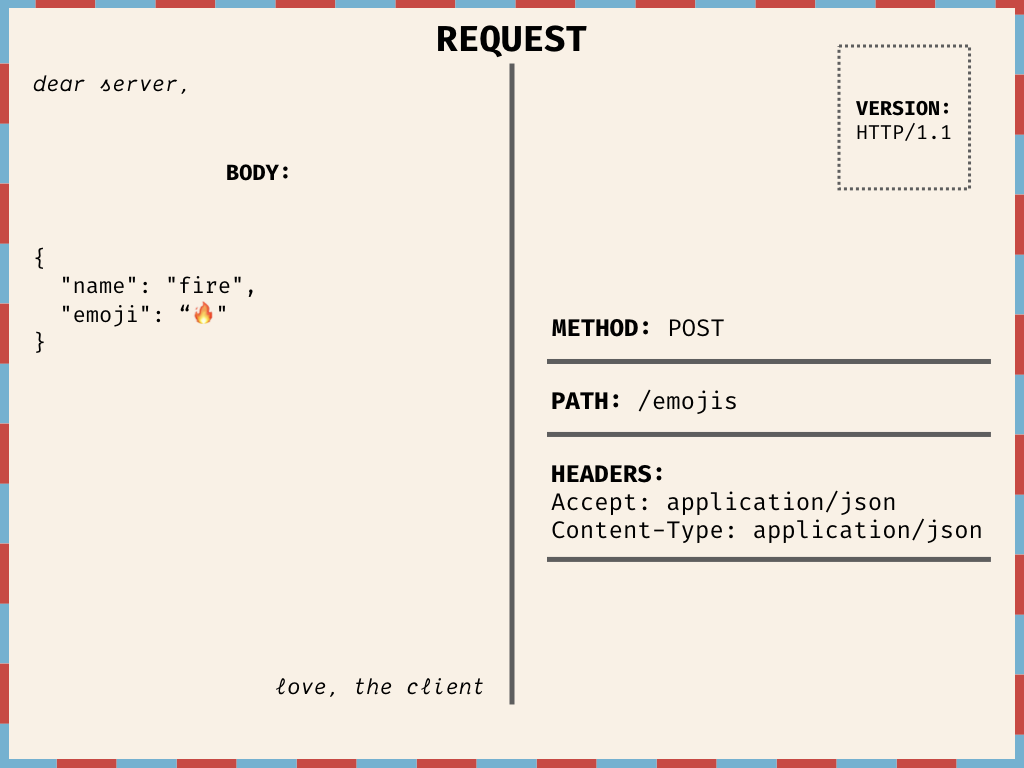

A sample HTTP POST request and response pair, presented as illustrations of postcards sent between the client and the server. The client attempts to create a new fire emoji with path emojis and the server responds with a 403 Forbidden status code and empty body.
Every postcard has a specific format and some fields that must be filled out in order to be sent.
The data flow is one-way, though. The client always make requests to the server — the server never initiates a request back. This means with HTTP you can’t “push” data to the client magically — you either have to poll the server by sending repeated requests over a set interval, or use a different protocol that does support two-way connections, like Websockets.
HTTP requests and responses are also stateless, which means that there isn’t any context shared between requests. Every request the client makes to the server is independent of any previous requests. The client can always include information in its requests that the server can use to identify it, and decide how to respond though! (That’s the point of cookies.)
Anatomy of a Request
A request is sent from the client, to the server, to start off a communication cycle.
Illustration of an HTTP GET request as a postcard. It uses HTTP/1.1, has a path of /emojis?type=food, with headers Accept: application/json. The body is empty. The postcard is addressed “Dear server” and signed “Love, the client.”
Illustration of an HTTP POST request as a postcard. It uses HTTP/1.1, has a path of /emojis, with headers Accept: application/json; Content-Type: application/json. The body contains a JSON string with a fire emoji icon and name. The postcard is addressed “Dear server” and signed “Love, the client.”
Requests contain the following fields:
-
VERSION: the exact version of the protocol being used
-
METHOD: the type of action the client wants to take
-
PATH: a URL that indicates what the client wants to take action on
-
HEADERS: optional metadata about the request
-
BODY: optional data
Anatomy of a Response
A response is sent from the server, to the client, to complete a communication cycle.
Illustration of an HTTP response as a postcard. It uses HTTP/1.1 and has a status code of 200 with status message OK. It has headers Content-Type: application/json. The body contains a JSON string with emoji names and icons for taco, sushi, and mango. The postcard is addressed “Dear client” and signed “Love, the server.”
Illustration of an HTTP response as a postcard. It uses HTTP/1.1 and has a status code of 403 with status message FORBIDDEN. It has headers Content-Type: application/json. The body is empty. The postcard is addressed “Dear client” and signed “Love, the server.”
Responses contain the following fields:
-
VERSION: the exact version of the protocol being used
-
STATUS CODE: a number that indicates whether if the success was successful, or why not
-
STATUS MESSAGE: a short description of the status code
-
HEADERS: optional metadata about the response
-
BODY: optional data
Let’s define these fields in more detail!
Fields for both HTTP Requests and Responses
VERSION
The exact version of the protocol the client is using, used in both requests and responses.
Most often version HTTP/1.1, but HTTP/2 is also possible! If the server doesn’t support the version of the protocol the client wants to use, it may not be able to understand or respond to the request.
HEADERS
Optional pieces of metadata about the request or the response.
Usually, headers contain information about the request/response itself, or preferences and options the client or server would like to communicate. Each request and response can contain multiple headers, or string key-value pairs.
Accept: application/json
This header is traditionally set on a request to indicates that the client wants the response data formatted as a JSON string. (The server still can do whatever it wants… but the client did ask politely.)
Headers can also be used to pass authentication data, set caching or Do Not Track preferences, pass cookies, indicate the application/operating system of the client, and much more.

Gif of Candace Wu in the Fresh Off the Boat TV show, looking confused with the caption “I need more information”. (source)
BODY
Optional data passed along with a request or a response.
{
"name": "fire",
"emoji": "🔥"
}
Traditionally, GET requests use the URL path and query strings to pass data about what kinds of resources they want, and POST / PUT / PATCH requests use the body.
Since responses don’t have a URL, they always pass data about the response via the body if the status code alone is insufficient information.
However, HTTP does allow you set the body of any request or response, so you can do what you want. If you do pass data here, you’ll probably want to include a Content-Type header to tell the recipient how to parse your string content!
Fields for HTTP Requests only

Gif of Lindsay Lohan in Mean Girls movie smiling and asking “So are you gonna send any candy canes?” (source)
METHOD
A word, usually a verb, that indicates what kind of action the client wants to take. Only set on requests!
Some common methods include:
- GET: fetch some data
- POST: create new data
- PUT: modify existing data
- DELETE: remove data
- OPTIONS: return what methods are supported
- and more!
Note that just because you can send a valid HTTP method to a server, doesn’t mean the server has to support that method for that URL — or that it has to take the action you request.
I could decide to write a server where calling GET /emojis deletes all the users in the database. This would be decidedly un-fun and you probably wouldn’t want to use my server, but it’s still a valid HTTP request/response.
The HTTP protocol doesn’t enforce that a server must respond to any of these methods, or what the implementation does — it just provides a list of options which is flexible enough to create whatever kind of contract you want.
PATH
The full URL, or where the client wants to take the action. Only set on requests!
Paths allow the sever to support multiple different types of data and resources! For example, I might want to serve /emojis, /gifs, and /puppies as separate endpoints.
https://www.mycoolsite.com/emojis?type=food
Let’s break down this sample URL:
https://indicates the protocol we’re using (sometimes also called a scheme)www.mycoolsite.comis the domain name, which will be translated by DNS into an IP address belonging to the physical host which is running the HTTP server for that address/emojisis the relative path we want to access on that host?type=foodis a query string, or a set of name-value pairs that give extra information about our request
Note that we didn’t specify a TCP port here! By default, HTTP requests will be directed to port 80. We could rewrite the same URL with the port specified as:
https://www.mycoolsite.com:80/emojis?type=food
Fields for HTTP Responses only
Gif of Daniel Franzese in Mean Girls movie, dressed as Santa Claus walking through a classroom full of students handing out candy canes from a stocking and saying “Glen Coco? Four for you. Glen Coco! You go, Glen Coco!” (source)
STATUS CODE
A number that indicates whether the request was successful, or why not. Only set on responses!
- 100-level responses are informational and just tell you metadata about the request.
- 200-level responses are successful and indicate everything went well! Common examples include
200 (OK)and201 (Created). - 300-level responses are redirections and indicate that the request won’t be completed. This isn’t necessarily an error. Common examples include
301 (Moved permanently)for paths that have changed, and304 (Not modified)for cached content that hasn’t been updated. - 400-level responses are client errors. Common examples include
400 (Bad request),404 (Not Found), and403 (Forbidden)for requests that are malformed, trying to access things that don’t exist, or that they don’t have proper authentication and authorization for. - 500-level responses are server errors.
500 (Internal server error)usually means the server has a bug, or503 (Service unavailable)often indicates the server is down.
Just like methods, HTTP doesn’t require servers to use these codes correctly. There are certain expectations that servers will response with the code that matches a given scenario, but they can use whatever code they want to and you can’t stop them.
It’s probably not worth memorizing a bunch of these codes, although you’ll certainly gain familiarity with the common ones over time. I like using sites with pictures for each code when I need to quickly reference which code to use.
HTTPBey has Beyoncé gifs for common status codes, and HTTP.cat has some rad cat pics (and you can easily access specific codes like http.cat/200).
STATUS MESSAGE
A short description of the status code. Only set on responses!
To help you remember what a status code is for, a short string is also set as the status message.
You should always depend on the numerical code in your application logic that handles responses, as servers can return whatever message they want and it may vary! But the text can be very helpful for quick debugging.
👩🏻🏫 Let’s Review!

Gif of Amy Poehler in Parks and Recreation TV Show, holding a hammer and smiling while saying “I’m learning so much already!” (source)
That was a lot of learning! Let’s review what we learned.
- Protocols are communication contracts. They provide different levels of abstraction, and we use lots of different protocols in order to send and receive data on the internet.
-
The Internet layer protocols (like the Internet Protocol, or IP) form the basic infrastructure of communicating between physical devices on a network (like roads and street addresses).
-
The Transport layer protocols (like the Transmission Control Protocol, or TCP) provide an abstraction around sending data. TCP in particular provides stronger guarantees about whether a message has arrived and ensures all the packets are assembled again in the right order (like a shipping logistics company).
-
The Application layer protocols (like the HyperText Transfer Protocol, or HTTP) are built on top of the other protocol stacks, like TCP/IP. They offer more specific features and abstractions for application purposes (like a local post office).
-
A server is any process running on a physical machine that listens to a specific port and implements a particular protocol. Web developers usually mean “HTTP server” when we say server, but you could also have an FTP or SSH server, etc.
Illustration of an HTTP POST request as a postcard. It uses HTTP/1.1, has a path of /emojis, with headers Accept: application/json; Content-Type: application/json. The body contains a JSON string with a fire emoji icon and name. The postcard is addressed “Dear server” and signed “Love, the client”.
-
HTTP is the application layer protocol most web developers interact with on a daily basis. HTTPS is the secure encrypted version, which you should always use to protect your users’ data!
-
HTTP consists of request and response pairs. Clients send requests, and servers send back responses. (Like postcards sent via our local post office!)
-
As developers, we expect that requests and responses are used in a particular way — like sending
GETrequests to fetch data and returning a200response to indicate a successful request — but HTTP does not require servers to implement specific behaviors! Servers can choose to do weird things, so be sure you understand the rules and contracts and options available to you before sending requests.
Now go forth and network with confidence! 🎉
Did you like this post? I’ll be sporadically publishing more content like this to the git checkout -b idk-what-im-doing blog in the future! Tweet me @mariechatfield to let me know what kind of resources you’d like to see next.
🙏🏻 Many thanks to Sarah Harvey for her feedback and networking expertise, and to my team at Pingboard for supporting my time writing these posts!
An emoji-filled learning journey about the trade-offs of different website architectures, complete with gifs, diagrams, and demo apps.
The best HTML elements you never knew existed, so you can improve your website's accessibility, mobile UX, and SEO while writing less code.