HTML vs. DOM | Marie Explains the Web
Learn how browsers use the HyperText Markup Language (HTML) and the Document Object Model (DOM) standards to turn text files into beautiful web sites.
December 20, 2020 • 3402 words • 12 minute read
This blog is a transcript of the YouTube video.
If you work on front-end web development, you’ve probably heard the terms “HTML” and “the DOM.” But what do they mean? Are they describing the same thing? How do they interact?
Join me to learn how browsers use the HyperText Markup Language (HTML) and the Document Object Model (DOM) standards to turn text files into beautiful web sites.

“HTML vs. DOM: Same? Different? How?” by Marie Chatfield Rivas.
Hi, my name is Marie Chatfield Rivas, and I am a senior software engineer with a passion for front-end web development. Thank you so much for joining me today! We are going to talk all about HTML versus the DOM.
These are two terms that you may have heard around in web development, and they’re often used somewhat interchangeably or very related to each other. So you may be wondering, are they the same thing? Are they different? How do they interact? And what do I need to know in order to build websites and do other front-end development?
HyperText Markup Language (HTML)

HTML (HyperText Markup Language): Language that marks up structure with content and meaning.
So let’s go ahead and get started with HTML, in other words HyperText Markup Language. HTML is a text language that marks up content with structure and meaning.
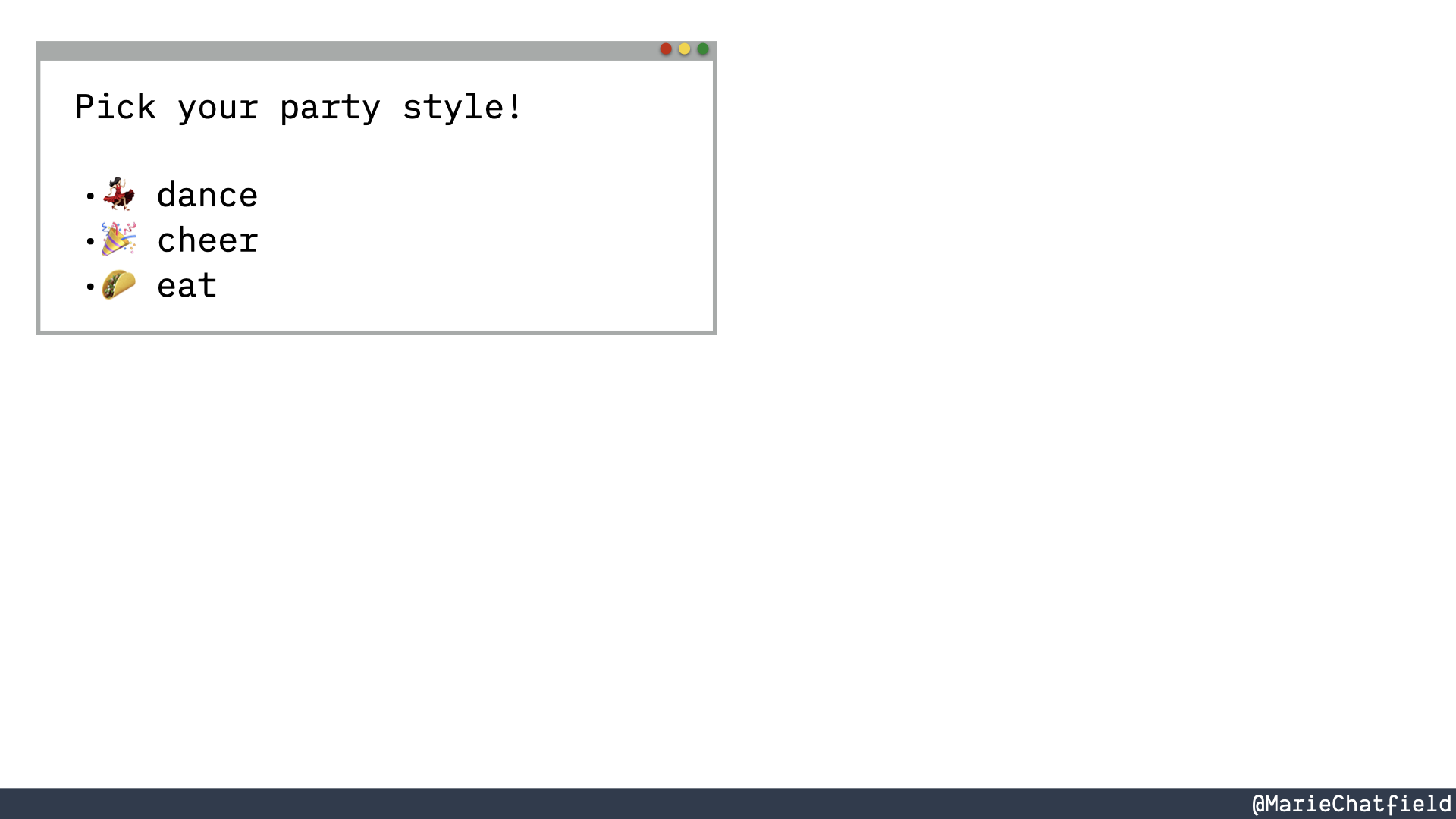
A browser with list of party styles, like “dance”, “cheer”, and “eat”.
And what I mean by that is that, say for example you know that the content that you care about is this text that says, “Pick your party style!” and then a list of different types of parties that you might like to go to.
Well, how would you communicate that to a browser?
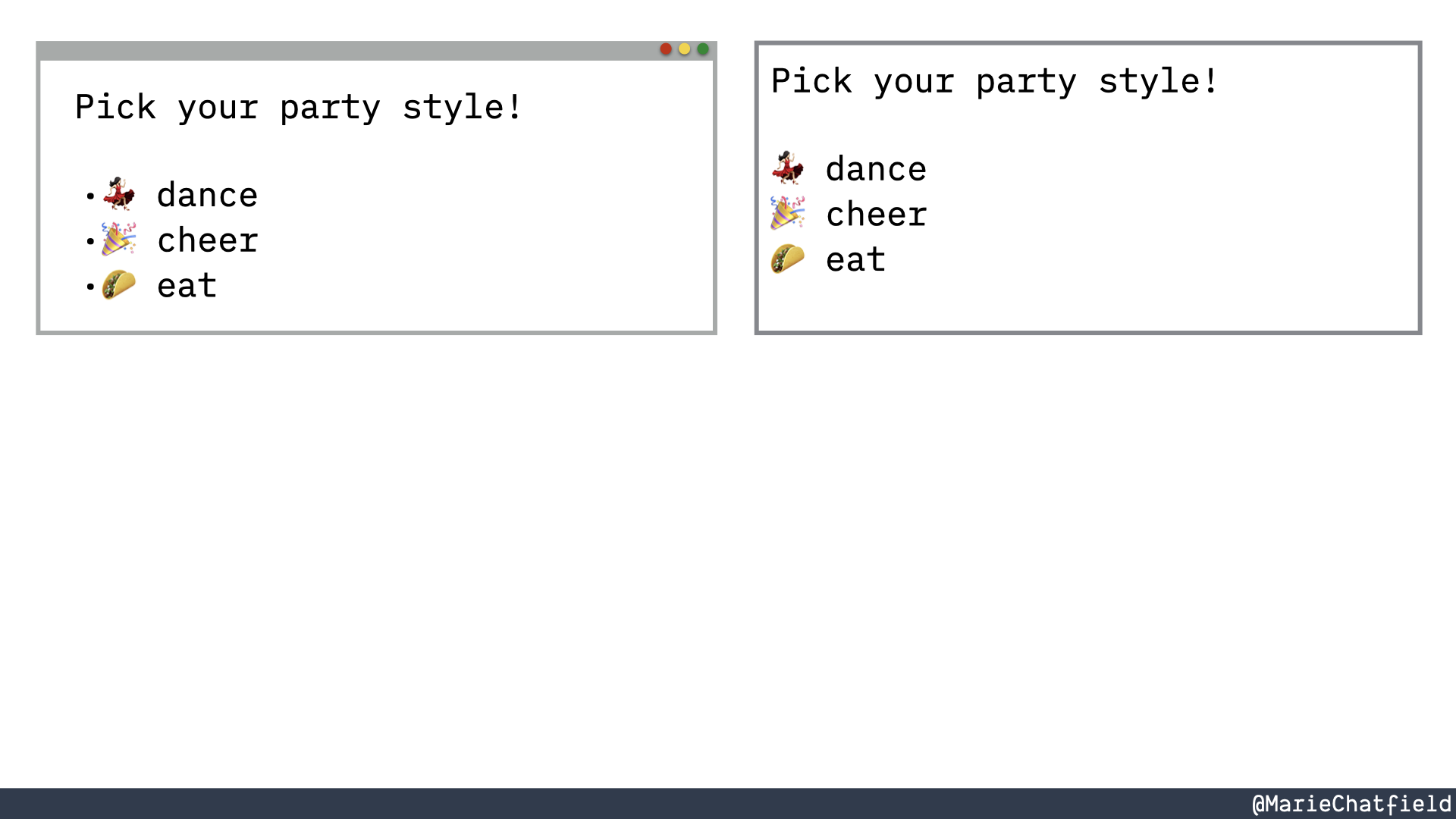
The list of party styles represented as plain text with no markup.
You could just put a text file that just has the actual text content that you want to display. But this really doesn’t say anything.
We know that we want a list, but there’s nothing in this structure, this just plain texts that indicates that. That’s where HTML comes into play.
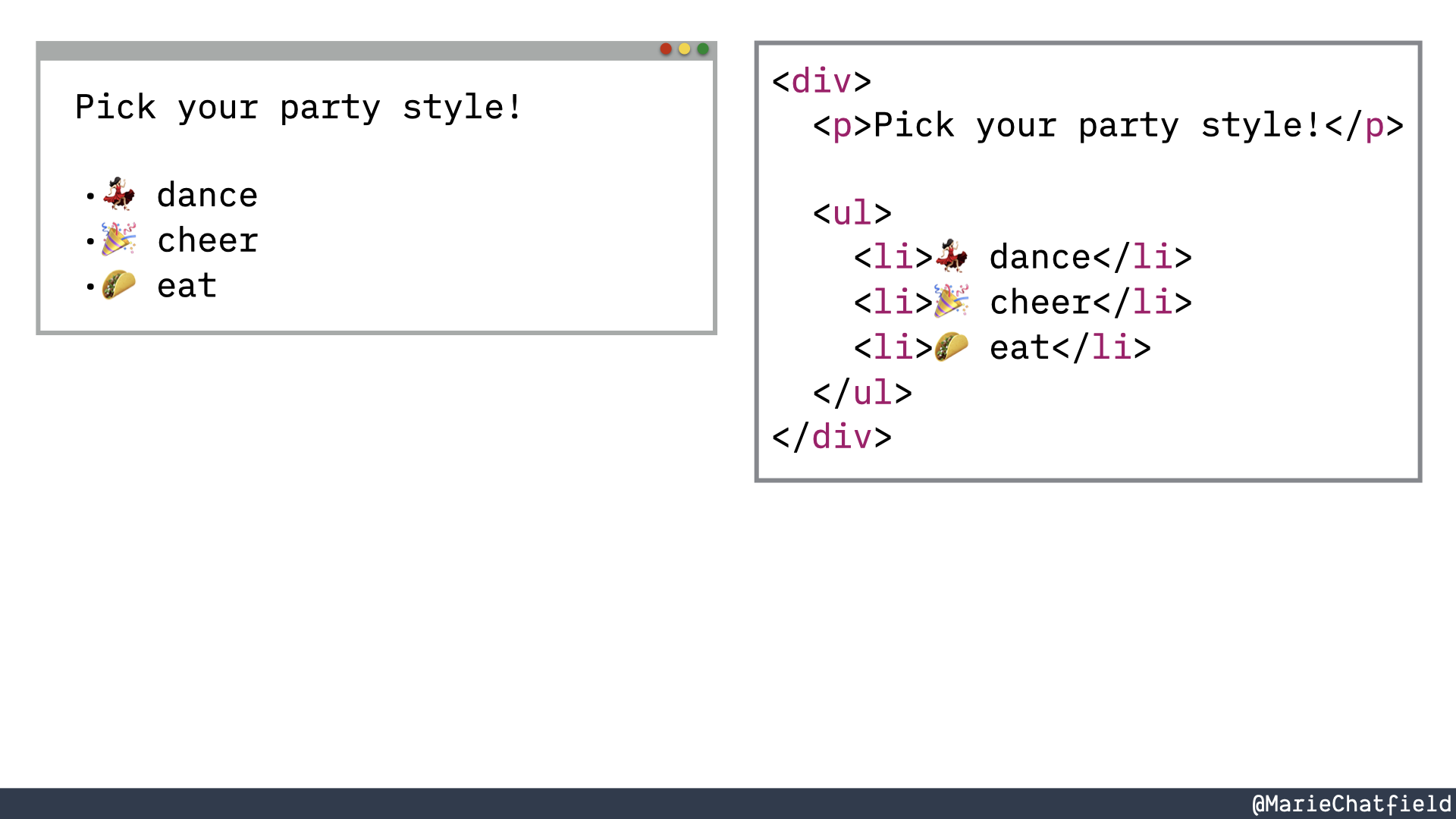
The list of party styles represented with <div>, <ul>, and <li> HTML elements.
So we’re able to mark up our content and give it some structure, say how things are related, as well as give it more meaning.
So for example, we have these <ul>, or unordered list, tag that then has children. That’s the structure bit. And each of those children is a list element the <li> tags that has some content inside of it.
So we know that there are supposed to be three elements in our list that each has some text content. We know how they’re related to each other. Then we know where it should fit into the rest of our page.
But this alone is not a full page.

The list of party styles in HTML markup, within a larger file with HTML elements like <html>, <head>, and <body>.
Usually this kind of HTML is found within the rest of your content. So it’s going to be an entire page.
So we’re going to see that we start out with something like this <html> element tag at the top of our HTML file, that is the parent of everything else. And usually we’re gonna start out with that <head> element that includes some metadata and information about the page itself, like for example, the title.
Then we’ll move down to usually we’ll have a <body> tag that’s describing more of the actual content of the page as a user would see it. Typically, it’s good practice to have a <main> element or sort of the main content of your page. What’s unique to this page. So not necessarily navigation, but the actual unique stuff.
And then finally all the way down in there we will eventually get to the actual content that we wanted to display, in this case, our list of party styles.
And one thing that you may note is it all of this is hierarchical. So we start out with that <html> top level tag and everything is a child of that element. And each of these element tags can have children, the children may be other HTML elements or it could just be plain text content.
But at the end of the day, this displays a lot more meaning and structure than just the plain text that we were looking at before. But this is still just a text file. You couldn’t exactly just send this to somebody and be like, “oh, hey, check out my webpage. Isn’t this really cool?” It’s got a lot of stuff in there.
So how does this become an actual webpage that looks the way that you expect? That’s where the DOM comes into play.
Document Object Model (DOM)

Document Object Model (DOM): API that describes how web pages work. Implemented by browsers.
The DOM is the Document Object Model, and this is an API that describes how webpages work, and it’s implemented by browsers.
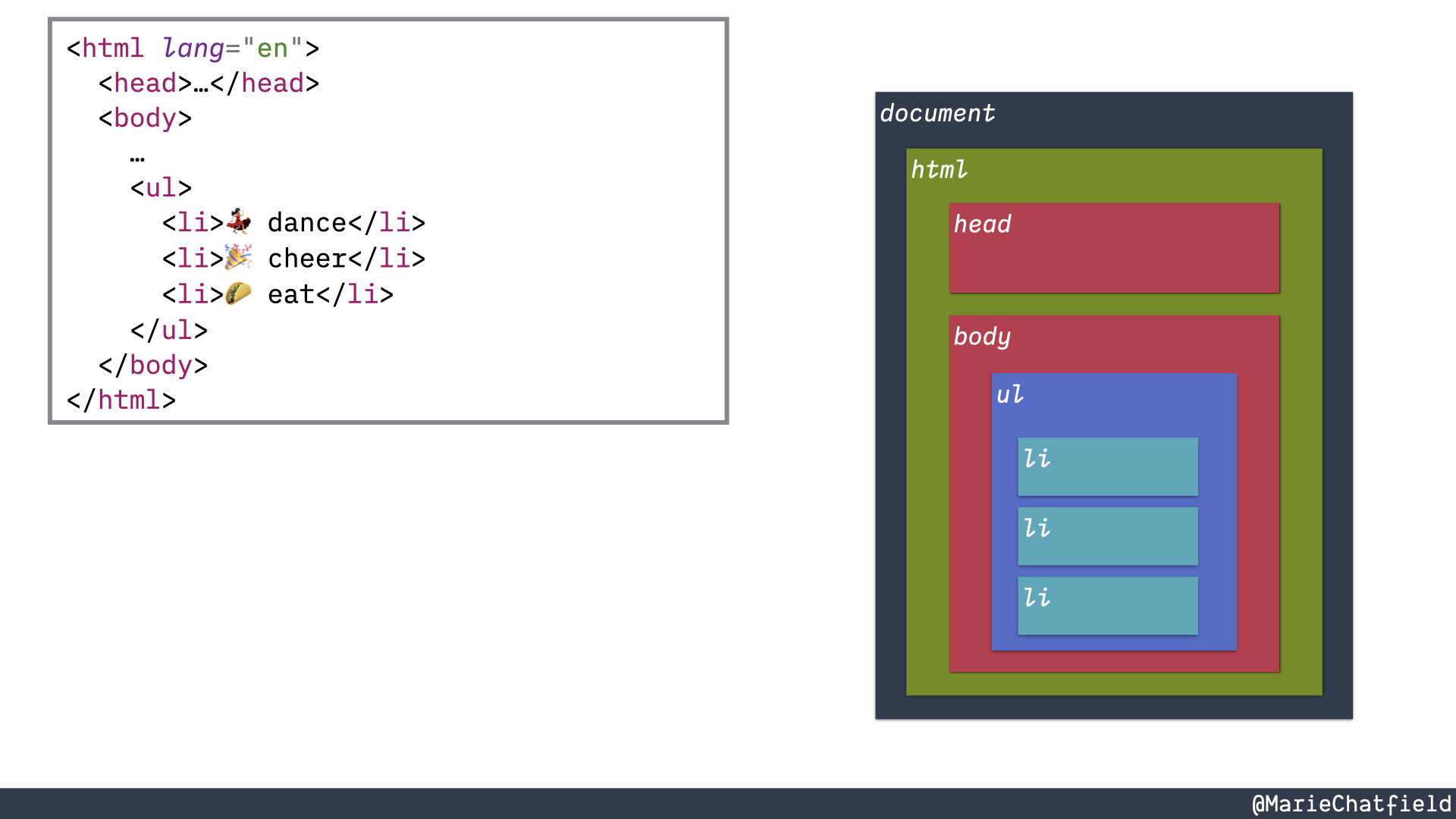
HTML text file outlining a page and a series of boxes representing the DOM nodes that match the elements.
So when a browser gets an HTML text file it uses the DOM APIs in order to figure out how to parse that text file into this hierarchical data structure that we sometimes call the DOM tree, because it’s a tree data structure
We can see that the top level object is this document. And then it has children. It has nodes inside of it. And they all map to the same HTML elements that we see in our text file. So there’s an <html> text element and that corresponds to the HTML DOM node. The <body> HTML element becomes a body DOM node, et cetera, all the way down.
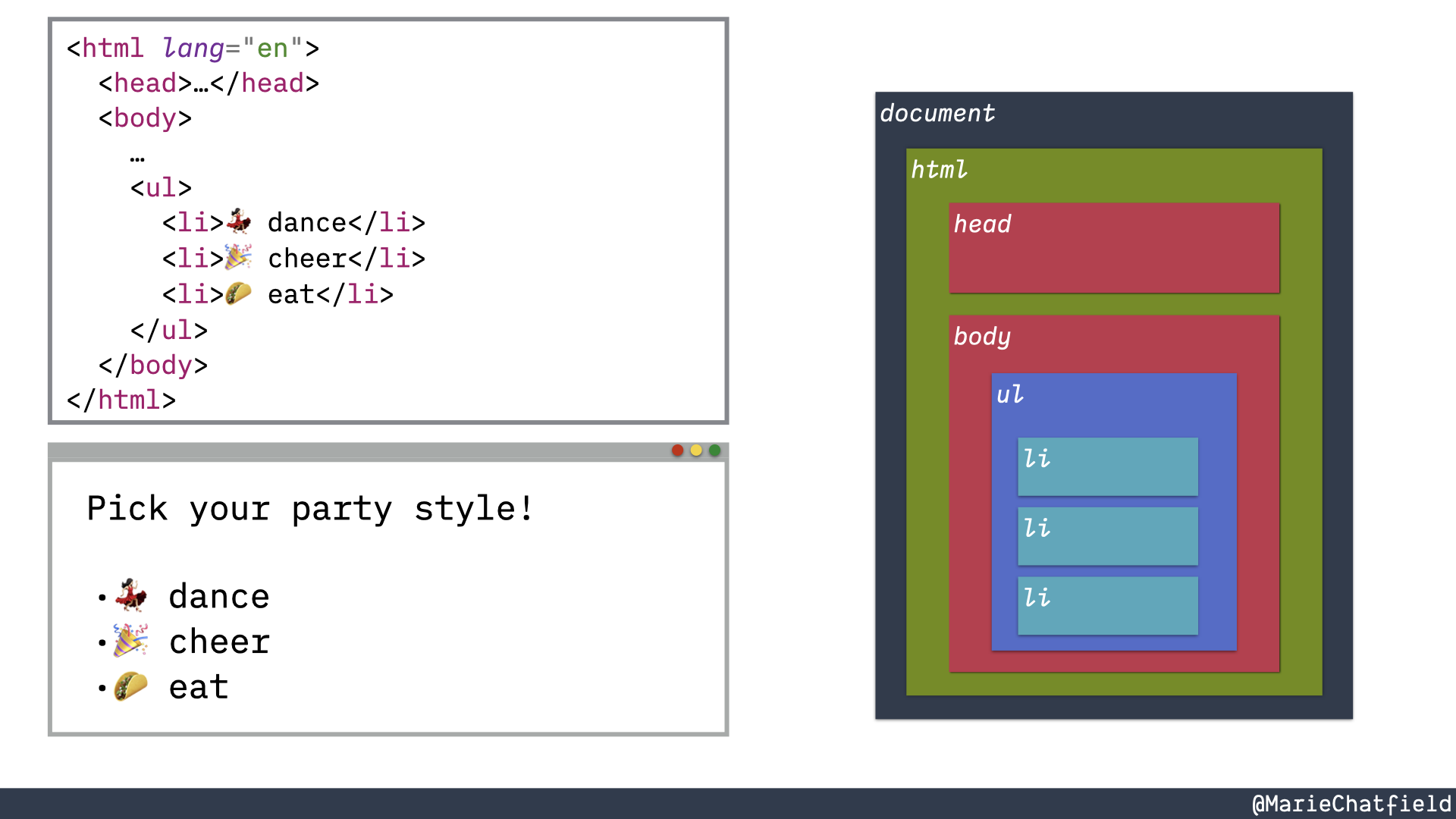
Browser with the same list elements defined in the HTML text file and the DOM nodes.
And then this is all internal data structure that the browser maintains and keeps up to date and keeps in sync. And it has a lot of extra properties and interesting behavior attached to each of these DOM nodes, everything that you need to make a webpage work.
So then the browser uses that internal DOM data structure, along with all the behavior that it represents, to actually render the webpage that you’re used to seeing and that your users can see and interact with.
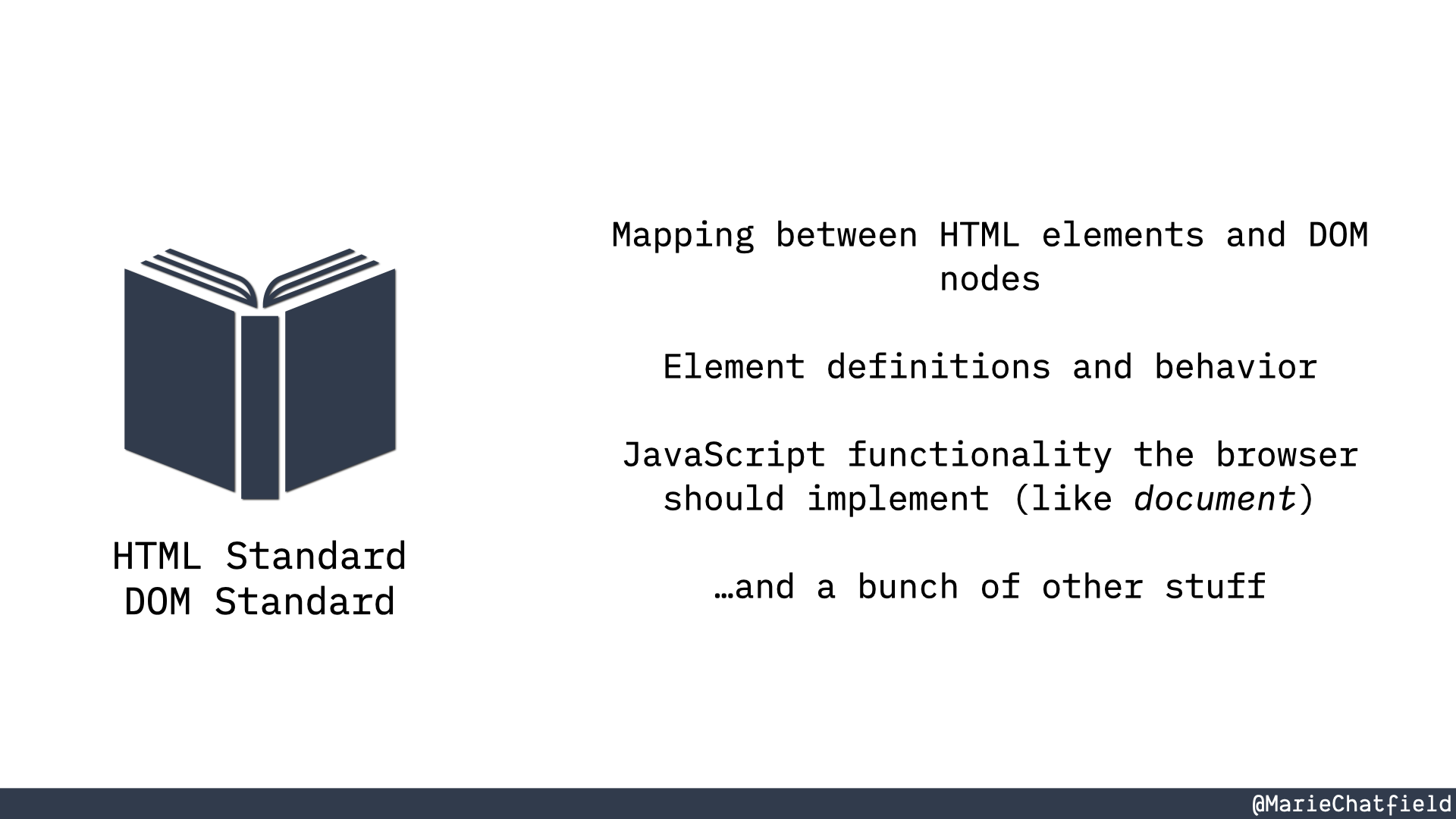
HTML and DOM standards include: mapping between HTML elements and DOM nodes, element definitions and behavior, JavaScript functionality the browser should implement (like document), and a bunch of other stuff.
So we can think of the HTML standard and the DOM standard as essentially like sets of rules. And these rules are going to include things like how do you map between an HTML element and a DOM node? As well as what should each of those elements do? How do they behave? What kinds of properties and attributes can you set on them? What should they look like? As well as JavaScript functionality that the browser should implement in order to access the DOM.
So for example, if you’ve ever used the document variable in JavaScript, that’s not native to JavaScript itself. It doesn’t come from JavaScript. That’s why it doesn’t always work if you’re in node writing server side code and you call document it might not actually be there. The document object is defined by the DOM API, and it has a set of JavaScript properties and functions that you can call on it in order to interact with the DOM as provided by the browser.
And there’s also a whole bunch of other stuff that these different APIs and standards implement and describe. It’s a really great idea if you have some time to go and start poking through them, reading through them. You’ll learn a whole bunch of stuff. And basically every single thing that happens on websites that you can write in a file and have it come to life, it’s described by one of these standards.
A Metaphor for HTML and the DOM
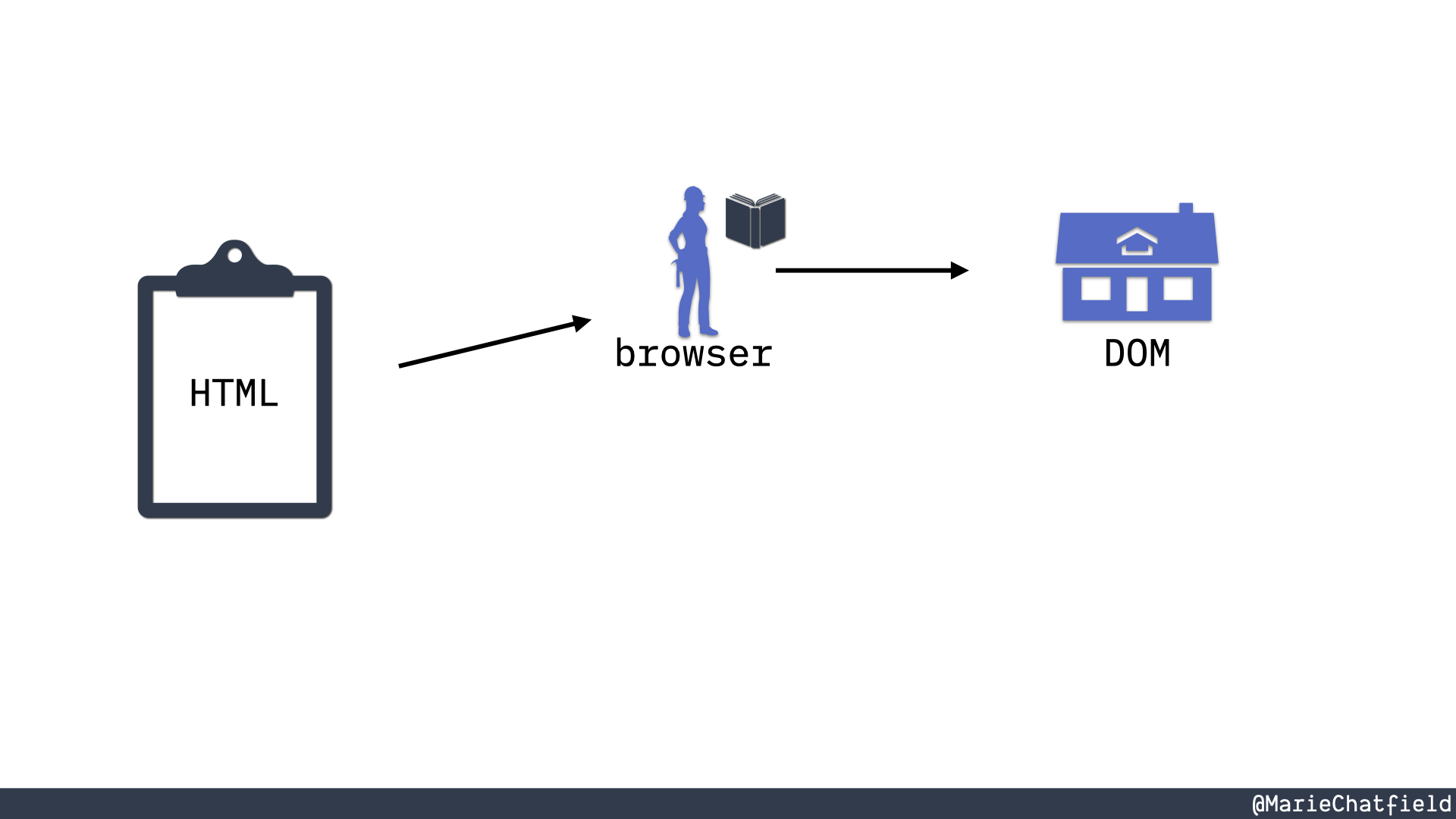
A set of plans (HTML) is given to a builder with a book (browser) that is turned into a house (DOM).
There’s a metaphor that I think is really helpful in terms of understanding how HTML and the DOM interact. So I like to think of HTML as house plans, like construction plans. So we can take this text HTML file, send that to a browser, and then the browser will read all of the standards and APIs around the DOM in order to figure out how to actually build a house from those construction plans.
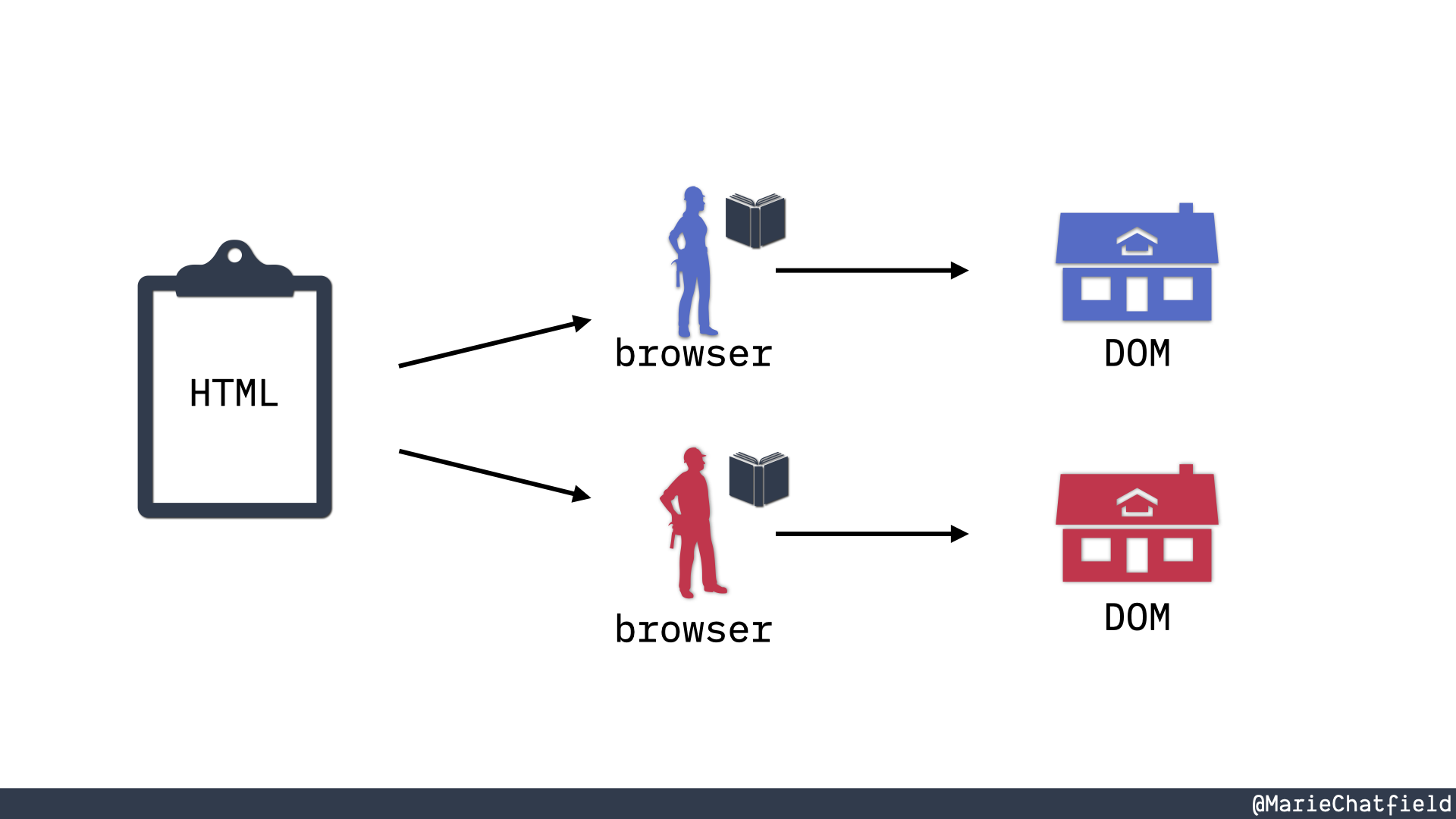
The same set of plans (HTML) is given to another builder with a book (browser) that is turned into another identical house (DOM).
And then in theory, if we send the exact same HTML text file to a different browser, it will reference those same APIs and standards in order to build a house that is pretty much the same.
We’re probably never gonna be exactly the same just because building a browser is incredibly complicated. These standards are massive and it’s very difficult to get them to consistently behave exactly the same way in every single scenario all of the time. So you may see some slight differences, but for the most part, these are gonna be the same house.
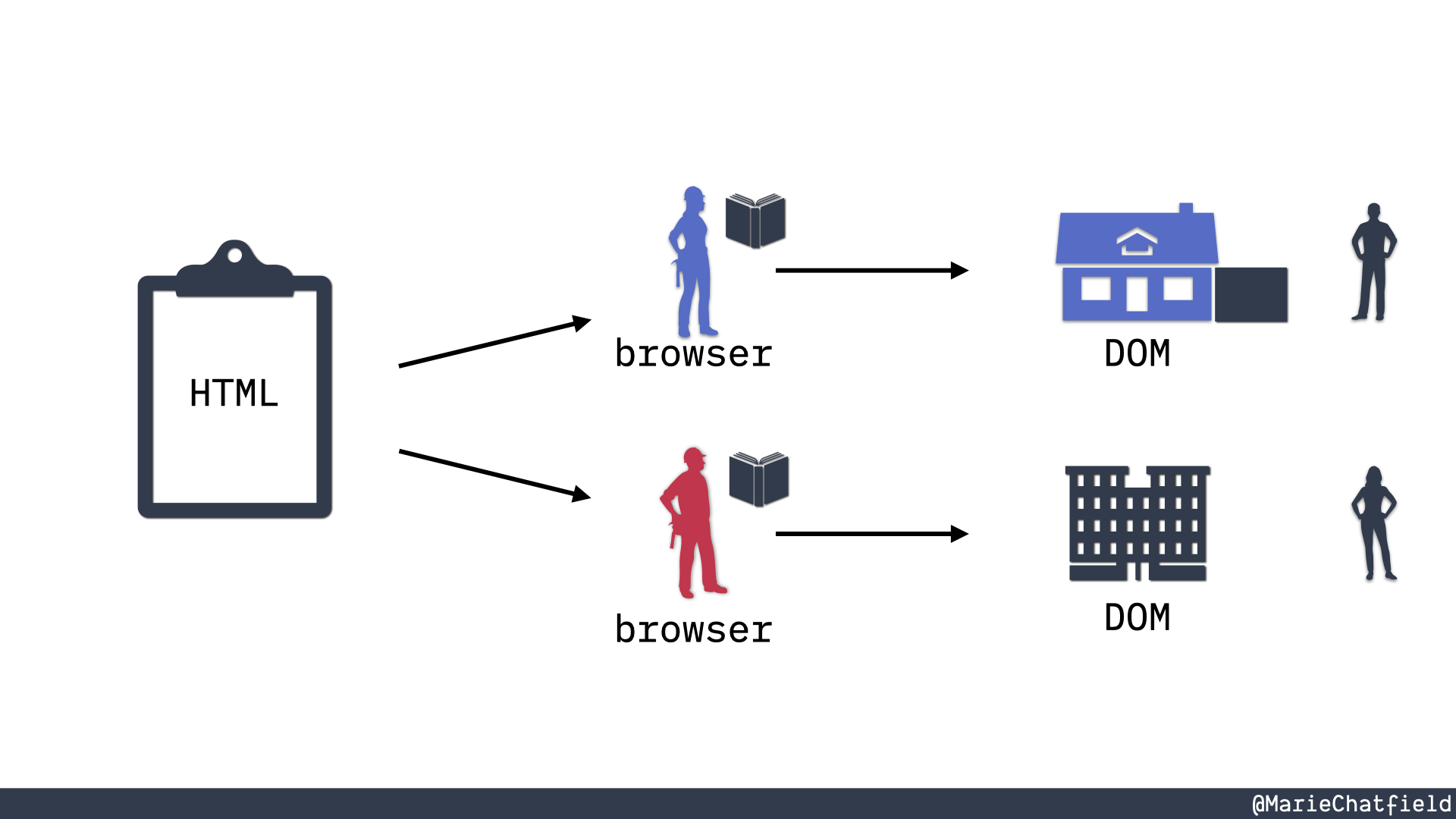
Two users standing next to the DOM houses, which have been modified or entirely replaced with a different building.
And then of course you have users interacting with your webpage, and as they cause events to happen, click on things, or do other stuff, usually the browser is going to interpret those with the DOM API and then make changes to the DOM as users are submitting forms or anything else.
At times, like let’s say, you’re using a single page app framework, so where you’re using JavaScript to entirely replace the contents of your page with something else. So the DOM that the user is seeing may look completely different from the DOM that was originally created from the HTML source file. And that’s totally okay. That is a thing that happens. But it all originated from the same place even though the DOM can go on and expand and be different.
Live Demo with Glitch
So why don’t we take a look at some code? I have here this lovely little Glitch app, and it has an HTML file, which looks really similar to the code that we were just looking at. We can see down here that we have this list and all of the elements.
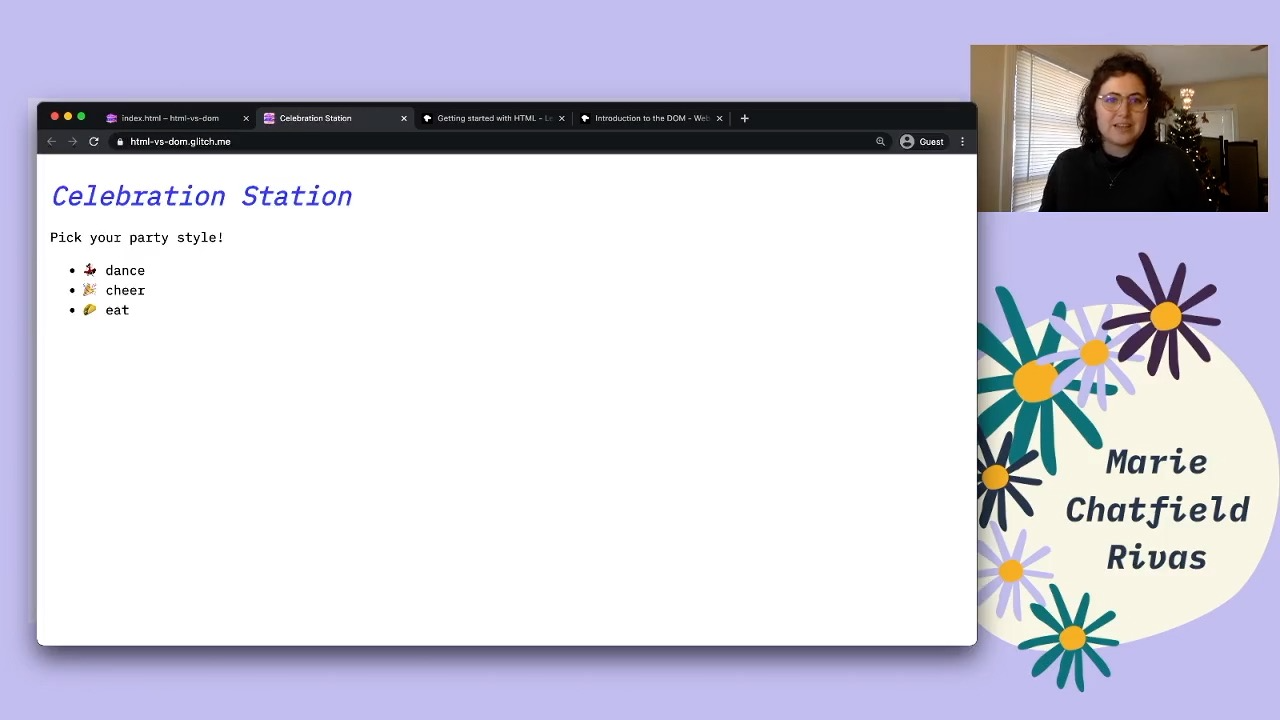
Rendered HTML in a browser with a list of party styles.
So let’s go ahead and look at this in the new page. So this is what we would expect to see. If we view the page source, we’re gonna see that this is the exact same HTML file that we saw that the server was going to render. Let’s go ahead and see if we can take a look at the DOM.
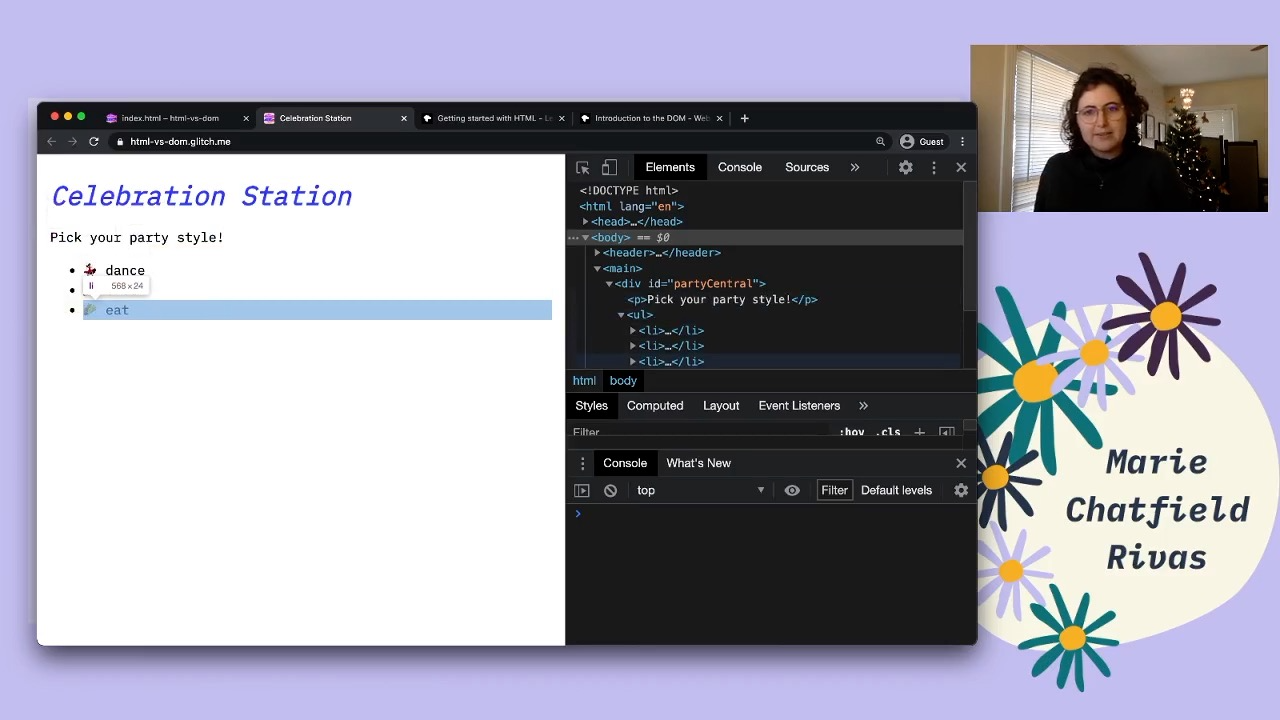
The same rendered HTML with the Developer Tools open to show the matching DOM tree.
So I’m gonna be doing all of this with the Chrome Developer tools, but pretty much all browsers have some way of accessing these developer tools. So here I can see a representation of my DOM tree. Once again, I see that I start out with this top level <html> element. I’ve got the <head> and the <body> as described in my HTML file and what’s once again, these are all the DOM nodes. I can click all the way down and see my list elements.
So I did mention that there is also JavaScript parts of the DOM. So for example, we can type document. And then we’re going to get the document object. This has a whole bunch of different functions and properties that you can use to access and do different things to interact with the DOM through JavaScript.
document.children
// HTMLCollection [html]
So for example, we can look at the children of the document object, and we see that it’s actually just this <html> element that we defined in our HTML text file that has now been transformed into a Document Object Model. And we can keep interacting with this.
document.children[0].children
// HTMLCollection(2) [head, body]
We can grab that <html> element and look at its children, and then we’ll see the <head> and the <body>. And we can just keep doing this forever, or we can also use different DOM APIs to interact with those things directly.
document.querySelector('li')
// <li>💃🏻 dance</li>
So for example, if you’ve ever done document.querySelector we can use this to use the CSS selector to grab an element out of the document, as long as it exists. So for example, I could say I want an element that matches the list element. And I’m just gonna grab the first one and then I can interact with this one.
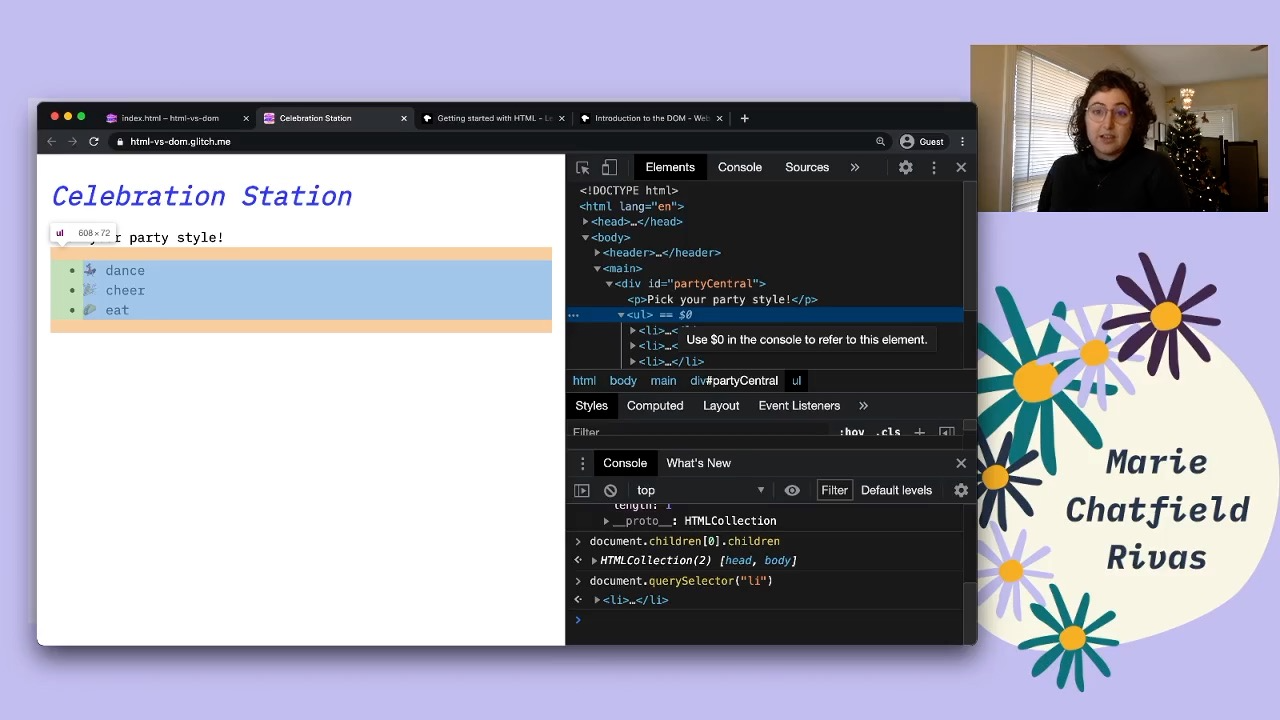
The Developer Tools open with a <ul> highlighted in the Elements tab. A tooltip is open which says “Use $0 in the console to refer to this element.”
There’s also a fun trick, by the way, at least in the Chrome Dev tools, not clear about other ones, but you can see here that if you have an element selected here in the DOM tree you can use $0 in the console to refer to this element, which just means that right now $0 is going to refer to my list element. And if I click something else $0, it’ll refer to that one.
I can also assign these to variables so that I can access them later. Or you can always right click and store as a global variable. This is really helpful if you’re debugging just to have some quick access to things.
So once again, the things, the variables that I’m working with now are actual DOM objects. And all of the APIs on them are defined by the DOM API, even though I’m accessing them through the JavaScript that’s provided by my particular browser.
So one thing to just show that the DOM is separate from the original HTML that generated this page is I can go ahead and just change the document. Normally this would happen as a result of, say, some JavaScript that you’ve written on the page, but we can just have some fun.
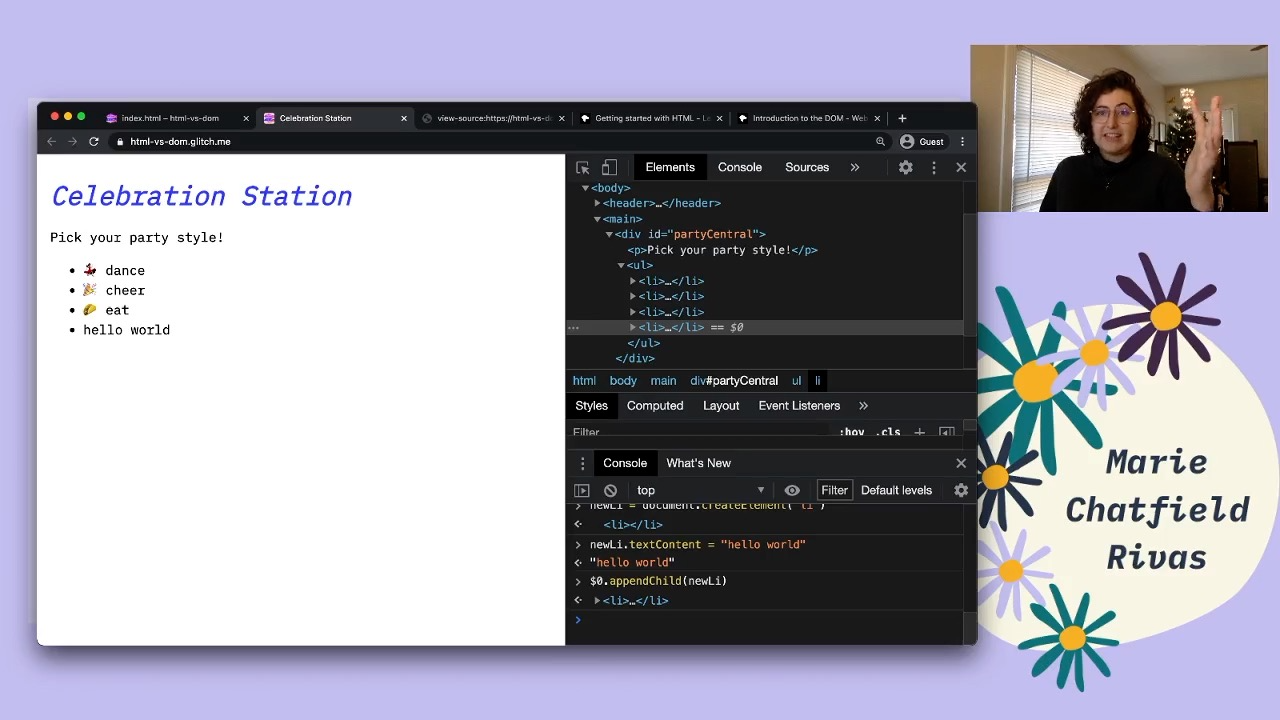
A new list element has been added to the rendered HTML and the DOM tree.
One interesting DOM API is the one that creates new elements. So if you are using something that is maybe React or Ember or Angular or Vue that’s doing some fancy rendering for you, they’re probably using this API under the hood in a way that you don’t have to write it yourself.
newLi = document.createElement('li')
// <li></li>
So I can create a new list element, and I’m just gonna call that document. And it has a function called createElement. And then I tell it the tag name that I want. In this case, just another list element.
newLi.textContent = 'hello world'
// 'hello world'
And then on this element I can now, let’s say set the text content to be hello world. Now this doesn’t actually exist anywhere in the DOM yet. I just have a reference to this element, but I can add it to the DOM.
$0.appendChild(newLi)
// <li>hello world</li>
So if I have my, oops, I have my unordered list, I can append the child, pass it my new list element. My DOM tree has been updated with the object that I just created.
But if we view the page source, this HTML file is still unchanged. This doesn’t necessarily stay in sync with the DOM. This is the text file that the browser used to create the initial version of this, but then the DOM tree does change over time. And that’s totally fine.
Conclusion
There’s a whole bunch of other fun things that you can do with the DOM API. Pretty much all events, interaction, it is what, for example is describing a list element typically has this little bullet and has some indentation and all of this other amazing stuff.
So if you’re wanting to learn more, I really recommend the Mozilla Developer Network documentation and particularly they have this “Getting started with HTML” page that kinda is gonna go through the basics of HTML, and then once you’re familiar with that, I really recommend their “Introduction to the DOM” documentation, which then talks a little bit about the DOM API and how it interacts with JavaScript, how you can access it.
And then in general, I would just say that the MDN Web Docs are a fantastic, they’re my go to documentation website. So if you do wanna look a little bit more into what properties and functions you can call on DOM nodes, this is a great place to go.

Marie waves goodbye!
Thank you so much for joining me today. I hope that that has given you a little bit more insight into exactly how HTML and the Document Object Model interact with each other in webpages.
Hopefully for my next video we’ll go a little bit into the differences between HTML attributes and DOM properties. In other words, the way that you can set things in HTML as initial value and then continue to update them and access them in JavaScript throughout the life cycle of your webpage. Things like value or event listeners or the types of inputs that you have on your page. That is definitely something that has bitten me in the past and been a source of confusion.
So check back another time and see if I’ve managed to create that video. And in the meantime, if you look below, there should be links to all of the resources that I have used today including the MDN Docs and the Glitch app that I was just demoing. Thank you so much and have a great day.
From onboarding to coaching, give your interns the tools they need to succeed—and set up your reports to lead them.